Not All Spaces Are Equal: The WhatsApp Bug That Wasn’t
Have you ever stared at your code, convinced it should work, and then realized the issue wasn’t logic, syntax, or structure — but a space?
Not a missing space… a wrong space.
This is a story of how invisible characters nearly broke my WhatsApp bot — twice.
The Bug That Shouldn’t Have Been
While building a WhatsApp automation bot, I wanted it to reply whenever someone sent a very specific message:
“I registered for MMC 2025. Please send me my free gift.”
I copied this phrase from WhatsApp, and pasted into the code, put everything in order, and then node index.js.
Everything worked fine, until I sent a message to the bot using a WhatsApp pre-filled message link like this:
1
https://wa.me/2348087654321/?text=I%20registered%20for%20MMC%202025.%20Please%20send%20me%20my%20free%20gift
…the bot failed to respond. It didn’t even recognize the message as matching the required phrase!
I typed in the message manually, and hit Enter again, but even then, nothing. It was a logic error, but I could not tell why it was happening. I read the message again, word for word, and checked the spelling, then rerun the code. Nothing.
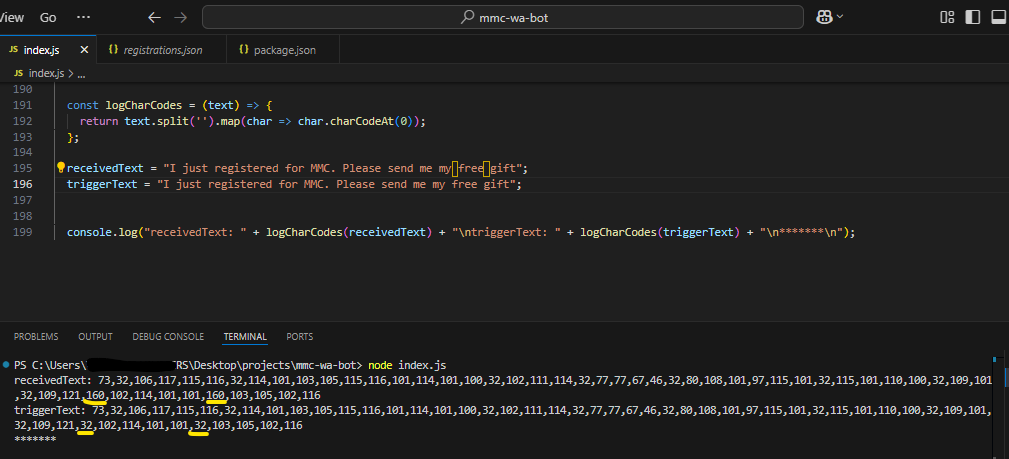
After rechecking my logic and print-debugging obsessively, I did something that finally helped: I used .charCodeAt() in JavaScript on the characters around the end of the sentence. That’s when I discovered the truth:
The “spaces” in the message weren’t
0x20(normal space characters). They were different Unicode characters that looked exactly like spaces — but weren’t.
You can look at this article’s picture to see (instead of charCode 32, I had 160.)
🔍 All Space is Not “Space”
This blew my mind. The text looked exactly the same in WhatsApp, VS Code, and even my browser dev tools. But invisible Unicode characters like:
- Non-breaking space (U+00A0)
- Zero-width space (U+200B)
- Thin space (U+2009)
…can sneak in when you copy text from platforms like WhatsApp, Telegram, or even formatted emails and web pages.
And the result? Your code breaks — but looks perfectly fine.
🌀 Déjà Vu in Python
A few months later, it happened again.
I was working on a Python bot that interacts with the Stellar blockchain. The bot needed a valid 12- or 24-word seed phrase (mnemonic). I copied one from WhatsApp, but Python kept rejecting it:
1
ValueError: Invalid mnemonic
Again, I was sure I had the correct phrase. Again, the problem was invisible characters.
🧼 The Fix: Clean Your Text
This time, instead of going full paranoia-mode, I found a helpful tool: textcleaner.net
I pasted the seed phrase into the input box, selected:
- ✅ Remove extra spaces
- ✅ Remove invisible characters
- ✅ Convert non-breaking spaces
…and clicked Clean. Boom. It worked.
Now I always sanitize copied text from WhatsApp before using it in code.
💡 What Can You Learn From This?
If you’re stuck debugging and everything looks right — consider this:
There may be nothing wrong with your logic. You’re just dealing with a sneaky Unicode ghost.
So:
- Use
.charCodeAt()(JS),ord()(Python), or hex viewers to inspect characters. - Avoid copy-pasting critical strings from messaging apps.
- Use text cleaners like:
🧠 Final Thought
All spaces may look the same, but they’re not treated the same. If your bot, validator, or parser is failing silently, ask yourself:
Is that really a space… or just pretending to be one?